https://unknown-alchemist.tistory.com/51
우선 파이어스토어는 위처럼 생긴 json문서 트리다.
그런데 이번에 제대로 작업을 하려고 하니
보안규칙이 또 헷갈렸다.
이번엔 완전판 느낌으로 정리해보려 한다.
사실은 크게 두 가지만 알면 된다.
문법이야 딱보면 알기 때문에
match문을 어떻게 구조적으로 활용해야 하는지,
조건으로 뭘 걸어야 제대로 걸어야 하고
각 키워드가 무슨 의미인지!
1. match 문의 의미
자, 아래 코드가 프로젝트단위의 파이어스토어의
어떠한 문서에 대한 트랜잭션도 조건없이 허용하겠다는 코드다.
service cloud.firestore {
match /databases/{database}/documents {
allow read, write : if true;
}
}1-1. service cloud.firestore { ...}
- 이건 파이어베이스의 타 서비스와 헷갈리지 않게 하기 위한 코드다.
1-2. match /databases/{database}/documents { ...}
- 단순히 해당 프로젝트의 모든 데이터베이스를 지목하는 코드다.
1-1 ~ 1-2 의 설명은 이 링크에 있다.
https://firebase.google.com/docs/firestore/security/rules-structure?hl=ko&authuser=0
1-3. 특정 문서 지목
아래는 모든 데이터베이스 허용보다 더 타이트한 조건을 걸어본 예시 코드다.
조건에 대해서는 2번에서 설명할 것이므로 구조만 보자.
service cloud.firestore {
match /databases/{database}/documents {
match /컬렉션이름/{가상의 문서이름. 향상된 for문 느낌} {
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;
}
}
}firestore 서비스의 이 데이터베이스 중,
특정 컬렉션 - 특정 문서에 일치하는 경로에 대해
read, write 동작은 이런 조건에서 허락한다!
라는 뜻이다.
여기서, match /컬렉션/문서변수 { ... }
이건 java의 향상된 for문과 비슷하다.
컬렉션은 자신의 <K,V> 데이터들 + 문서집합을 가질 수 있으므로
컬렉션 하위의 문서집합에 대해 하나씩 검사하는 것이다.
java코드로 치면 아래 비슷하다.
확 이해됐을 거라고 본다.
for (Document document : Collection.getDocuments()) {
if ( ... ) {
document.read();
}
if ( ... ) {
document.write();
}
}
1-4. 재귀 와일드카드
그런데 한 컬렉션 안에 있는 문서들 뿐만 아니라
한 컬렉션의 문서집합들이 조건을 통과하면
그 이하의 모든 문서에 대해서도 통과됐다고 볼 수 있지 않은가?
그 때는 하위 문서까지 적용되는 규칙인 '재귀 와일드카드'를 적용할 수 있다.
이렇게.
service cloud.firestore {
match /databases/{database}/documents {
match /컬렉션이름/{document=**} {
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;
}
}
}"{document=**}" 라고 써진 곳이다.
이 방법을 쓰면 지정한 컬렉션 하위의 모든 문서에 대해
블럭 안의 규칙을 적용하겠다는 뜻이다.
1-5. 동일 레벨의 match문
이러면 어떨까?
read 혹은 write 요청이 왔는데
컬렉션1의 하위문서에 대해서는 조건이 걸려있고
컬렉션 2의 하위문서에 대해서는 무조건 거부라면?
모든 요청이 거부될까?
아니다.
공식문서에도
이렇게 동일 블럭 레벨에서 조건을 걸면
'OR' 조건이라고 한다.
하나라도 true 라고 결정되면
클라이언트의 요청은 허용된다.
service cloud.firestore {
match /databases/{database}/documents {
match /컬렉션이름/{가상의 문서이름. 향상된 for문 느낌} {
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;
}
match /컬렉션이름2/{가상의 문서이름. 향상된 for문 느낌} {
allow write : if false;
allow read : if false;
}
}
}
1-6. 내부 match문
이러면 또 어떨까?
특정 컬렉션 하위 문서에 조건을 걸고,
그 안에 match 문이 또 있다.
service cloud.firestore {
match /databases/{database}/documents {
match /컬렉션이름1/{가상의 문서이름. 향상된 for문 느낌} {
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;
match /컬렉션이름1 하위 컬렉션/{가상의 문서이름. 향상된 for문 느낌} {
allow write : if false;
allow read : if false;
}
}
}
}
이럴 경우에는 우선 특정 컬렉션 하위 문서까지의 경로를 match문이 이어받는다.
예를들어
collection1 { document1{ collection2 { document2 } } }
이렇게 자식이 하나씩 밖에 없는 트리가 있을 때
match /collection1 / {document} {
match /collection2 / {document} {
}
}
여기서
match /collection2 /{document}
== match / collection1 / document / collection2 /document { ... }
인 것이다.
그래서 결론은
블럭안의 match 문이 모든 요청을 거부하고 있으므로
거부로 결과가 나오게 된다.
1-7. 모든 문서의 규칙이 있어야 함.
여기서 가장 많이 헤맸는데 아마 공식문서 어딘가 설명이 있겠지만
다 읽어보질 않았다.
특정 경로의 문서에만 규칙을 걸면 안 되고
요청한 경로 아래에 있는 문서들에 규칙이 있고 true 가 결과로 나와야 한다.
3번의 그림을 보면 바로 알게 될 것이다.
2. 조건으로 활용가능한 것들의 의미
일단 제일 도움됐던 문서다.
https://firebase.google.com/docs/reference/rules/rules.firestore.Request?authuser=0#auth
https://firebase.google.com/docs/reference/rules/rules.firestore.Resource?authuser=0
이제 match 로 특정 경로를 특정했는데,
어떤 기준으로 어떤 요청을 허락하고 거부할지 정해야 한다.
그 전에 이 것도 알아야 한다.
2-1. read, write
read 규칙은 get과 list 로,
write 규칙은 create, update, delete 로 나눌 수 있습니다.
read write 만 있는게 아니다.
필요에 따라 잘 활용해야 하지만 아직 나에겐 해당되는 내용이 아니다.
2-2. if
자 이제 2-1 의 각종 요청을 어떤 조건으로 분별할지가 if 안의 내용이다.
사실 resource 와 request 에만 익숙해져도 별거아니다.
모두 허용
allow read : if true;
allow write : if true;
모두 거부
allow read : if false;
allow write : if false;
내가 쓴 조건
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;-> 요청한 문서의 ID (문서이름) 가,
바꿀 문서의 ID 와 같으면 허용
resource.id : 원래 파이어스토어에서 가지고 있던 문서의 ID
request.resource.id : 들어온 요청에서 확인된 문서의 ID
여기서 문서의 데이터 필드도
resource.data.필드키,
request.resource.data.필드키
로 가져올 수 있다.
만약 인증정보를 활용하고 싶다면
아래와 같이 접근할 수 있다.
역시나 위 링크에 다 나와있는 내용이다.
request.auth; request.auth.uid;
3. 정리
이제 다시 돌아가서 처음 규칙코드 전체를 보겠다.
service cloud.firestore {
match /databases/{database}/documents {
match /콜렉션/{문서변수} {
allow write : if resource.id == request.resource.id;
allow read : if resource.id == request.resource.id;
match /하위콜렉션1/{document=**} {
allow read : if true;
allow write : if true;
}
match /하위콜렉션2/{document=**} {
allow read : if true;
allow write : if true;
}
}
}
}read 나 write 요청이 들어오면
원래가지고 있던 콜렉션의 문서들을 쭉 보면서
각 문서의 ID 가 같은 경로의 문서 ID 와 같은지 검사한다.
read/write 둘 다 같은 검사를 한다.
만약 문서의 ID가 일치한다면
하위콜렉션들의 문서도 재귀 와일드카드를 활용해서
모든 트랜잭션을 허용한다.
이게 끝이다.
이걸 그림으로 표현해봤다.
콜렉션 아이콘 :

문서 아이콘 :
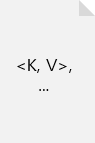

android / java 환경에서 정보를 쓰든 읽든
아래와 같은 코드가 들어간다.
Firestore.getInstance()
.collection("이름")
.document()
.set(DocumentReference, Map<K, V>); //이하 리스너
Firestore.getInstance()
.collection("이름")
.document()
.get(); //이하 리스너인스턴스(루트)를 얻고
특정 경로를 얻어서 read 혹은 write 종류의 요청을 하는 것이다.
이러면 request 는 항상 경로와 데이터를 가지고 있기 때문에
규칙이 있다면 규칙과 비교해서 트랜잭션을 수행할 수 있는 것이다.
위 그림은 이런 과정을 나타낸 것이다.
특정 앱 / 특정 집합 / 특정 데이터에 대해 트랜잭션을 하려면
하위 문서까지의 조건이 모두 일치해야 쓰던지 읽어올 수 있는 과정이다.
root 에서 뻗은 문서 중에
가운데 가지의 트랜잭션 과정을 나타냈다.
왼쪽은 이미 데이터를 서버에서 가지고 있으므로
다른 데이터 까지 가지고 있고 이 데이터를 가져올 때
resource.data 가 되는 것이고,
오른쪽은 특정 경로를 특정한 다음 요청을 했기 때문에
다른 데이터는 모르고 특정 경로만 가지고 있다. 그리고
request.resource.data 로 데이터를 가져올 수 있다(read 종류라면 의미없을 것이고)
일단 여기까지만 쓰고 마무리하겠다.
'Android' 카테고리의 다른 글
| [Android] 진동컨트롤(Vibrator) (0) | 2022.11.03 |
|---|---|
| [Android] 커스텀 뷰, 원형 프로그레스 구현기 (0) | 2022.10.06 |
| [Android] Snackbar(스낵바) 띄우기 (0) | 2022.09.05 |
| [Android] Read contacts(연락처 가져오기) (0) | 2022.08.30 |
| [Android] Room 을 사용한 초기 DB구축(외래키(Foreign Key / FK), UNIQUE 포함) (2) | 2022.08.21 |

